Series Overview
This article is Part 2.3 of a multi-part series: “Development of system configuration management.”
The complete series:
- Introduction
- Migration end evolution
- Working with secrets, IaC, and deserializing data in Go
- Building the CLI and API
- Handling exclusive configurations and associated templates
- Performance consideration
- Summary and reflections
Exclusive Hosts Configuration
Purpose and Requirements
The minimum configuration unit for the new SCM is a host group that performs a similar function in the infrastructure. In other words, we can define this as a role for the hosts. Each role has an environment that describes the host’s belonging to a dedicated set for different purposes. For example, a role called backend can have three environments: prod, stage, and dev in the project myproj. As a result, these names define the hostgroup:
- myproj-dev-backend
- myproj-stage-backend
- myproj-prod-backend
Each host group consists of a certain number of hosts, which can sometimes include just one host. However, an important principle that has long been established is that we cannot configure objects smaller than a hostgroup using the new SCM. This approach is logical, as host groups are used to enable multiple hosts for horizontal scaling and ensure high availability for each service. In most cases, such hosts share a similar configuration, and we operated under the paradigm that if we needed to configure only one host without a hostgroup, we were likely doing something wrong.
However, we eventually concluded that there are instances where more detailed configurations are necessary than those applicable to a host group. There are also many cases where we need to apply configurations to one or more hosts within a particular hostgroup. A special case of this might involve applying configurations in a canary manner to one or a few hosts to minimize the impact on the rest of the hostgroup.
In the early stages of developing the new SCM, we used a workaround involving stopping the SCM agent or locking updates on some hosts. This allowed us to test deployments on smaller subsets of the host group before applying the configuration to the full group. However, this approach has several obvious issues:
- Testing subsets of servers prevents them from receiving new configuration updates, affecting not just the part that is currently being tested.
- Testing subsets of servers stops checking the verification of the state of the configuration. For instance, the SCM agent verifies that the necessary services are running.
- These manual operations do not improve overall automation.
In accordance with the above, the following requirements for exclusive configuration have been established:
- The ability to create configurations per host or for a few hosts
- The ability to create specific configuration blocks that do not interfere with other modules
- The ability to control exclusive configurations remotely to meet CI/CD needs
Possible Ways to Implement This
When we started analyzing possible ways to implement exclusive configurations, we faced a key question: where should we store the configurations? Essentially, we had two options.
Firstly, it can be stored as a simple file, similar to a hostgroup YAML file. This file should have a higher priority compared to the group configuration. However, this approach is not very useful because it does not address the third requirement. It cannot be used from CI without workarounds. Although we ultimately did not choose this option, it became feasible to use it indirectly later, after enabling templating for YAML files:
{{- if eq .IP "10.10.10.10" }}
configuration for this host only
{{- else }}
configuration for other hosts in hostgroup
{{- end }}Secondly, we considered using an API router for exclusive configuration control. In this case, we can control configurations remotely with proper authorization. Since the API uses Consul to store data, the configuration received through the API can be saved in Consul by the SCM, which can then utilize these keys in the scheduler to build the complete host configuration. This solution satisfied all requirements.
In practice, implementing this was relatively straightforward — we added this logic at the CLI level of the deployment tool, which processes requests for individual hosts. The API saves this data in a dedicated path: exclusive/host/{ip}. The scheduler then connects to this path when merging configurations, allowing for different configurations for each host. The merged configuration of hosts takes precedence, and any previously declared configurations can be overwritten by these specific settings.
We began using this configuration to implement rollout deployment logic similar to that of Kubernetes for non-Docker projects. All of the logic was integrated at the CLI level, where the tool recognizes the number of hosts in hostgroups, performs deployments across the specified number of hosts, and waits for them to run.
Implementation in the Code
A route api/v3/exclusive has been added to the API that provides a CRUD interface. To add an exclusive configuration, send an HTTP POST request with the following structure:
type ExclusivePostData struct {
Section string `json:"section"`
Hosts []string `json:"hosts"`
Ttl int `json:"ttl"`
Data string `json:"data"`
Immediately bool `json:"immediately"`
}Where: section is the context name for the resulting JSON sent to the selected hosts. data is the JSON containing the configuration data. hosts are the selected hosts. ttl is the total time to store this key in Consul. immediately specifies whether to deploy immediately using the push approach.
Once the API router has received all the necessary data, it saves the key in Consul:
consul:~$ consul kv get -recurse exclusive/10.9.2.116/
exclusive/10.9.2.116/packages:{"iftop":{}}As mentioned earlier, we needed to update the configuration generator. We added another merge to enrich this per-host configuration:
// merge configuration tree with consul exclusive data
err = mergo.Map(&DefaultConf, ConsulExclusive, mergo.WithOverride, mergo.WithAppendSlice)
if err != nil {
logger.GenConfLog.Println("mergo Map failed with DefaultConf and ConsulExclusive")
return map[string]interface{}{}, err
}The mergo.WithAppendSlice flag is particularly useful in this case, as it allows us to add information to a slice instead of replacing it.
Two methods, GET and DELETE, have been implemented for creating and deleting exclusive configurations.
How to Use This in Practice
The exclusive command has been added to the CLI tool, enabling it to operate with the exclusive API route on the SCM API.
~$ cli exclusive --help
NAME:
cli exclusive - Get/push/delete exclusive configuration for host(s)
USAGE:
cli exclusive command [command options] [arguments...]
COMMANDS:
push push exclusive configuration for host(s)
get get current exclusive configuration for host(s)
delete delete exclusive configuration for host(s)
help, h Shows a list of commands or help for one commandOne example of how exclusive configurations can be beneficial is in canary deployments. The following script was implemented for use in CI:
- Sending an exclusive configuration to the SCM Nginx module to remove one upstream host from the load balancing pool
- Sending an exclusive configuration to the SCM Docker module to update the Docker image on the host
- Using various checkers to test the application for updates and health
- Removing the exclusive configuration from the SCM and then enabling traffic for the updated backend
- Repeating this for each host in the subset
Disadvantages of Using Exclusive Configurations
The main disadvantage of exclusive configurations is their opacity; users may forget that they have been created. While there is a TTL functionality that allows configurations to revert after a specified time, the use case for TTL is primarily suitable for testing.
Metrics and Logs
Pull SCM agents can’t provide detailed information when functioning in ways other than through logs and metrics. We implemented different loggers at both the agent and API levels. This improvement enhanced observability and debugging during the development of our SCM and remains useful now that active development is finished.
Many loggers write to multiple files based on their area. Any references to the file module are logged in ‘file.log’, service-related logs go to ‘service.log’, and package-related logs are written to ‘package.log’. What about the other modules? Yes, each module has its own designated log file, such as:
- aerospike.log
- nginx.log
- clickhouse.log
- etc.
At the API level, configuration mergers write logs to their respective files. Similarly, at the SCM agent level, parsers also log to the relevant files. The implementation for this is quite simple:
func LogInit() {
PackagesLog = CreateLog(conf.LogPackagesPath, "packages")
ServicesLog = CreateLog(conf.LogServicesPath, "services")
VaultLog = CreateLog(conf.LogVaultPath, "vault")
AerospikeLog = CreateLog(conf.LogAerospiketPath, "aerospike")
PKILog = CreateLog(conf.LogPKIPath, "pki")
DiskLog = CreateLog(conf.LogDiskPath, "disk")
UserLog = CreateLog(conf.LogUserPath, "user")
}
func CreateLog(LogPath string, Component string) (*log.Logger){
file, err := os.OpenFile(Path, os.O_CREATE|os.O_WRONLY|os.O_APPEND, 0660)
if err != nil {
log.Fatalln("Failed to open log file", Path, ":", err)
}
retLogger := log.New(file, ": ", log.Ldate|log.Ltime|log.Lshortfile)
SyslogPrefix := os.Getenv("SYSLOG_PREFIX")
SyslogAddr := os.Getenv("SYSLOG_ENDPOINT")
SyslogProto := os.Getenv("SYSLOG_PROTO")
if SyslogPrefix != "" && Component != "" {
TagName := SyslogPrefix + "-" + Component
if SyslogAddr != "" {
if SyslogProto == "" {
SyslogProto = "udp"
}
syslogger, err := syslog.Dial(SyslogProto, SyslogAddr, syslog.LOG_INFO, TagName)
if err != nil {
log.Fatalln(err)
}
retLogger.SetOutput(syslogger)
} else {
syslogger, err := syslog.New(syslog.LOG_INFO, TagName)
if err != nil {
log.Fatalln(err)
}
retLogger.SetOutput(syslogger)
}
}
return retLogger
}Syslog serves as an alternative way to monitor issues across the infrastructure. Syslog messages are received by the local rsyslog and sent to ElasticSearch.
The most challenging aspect is logging the differences in files due to potentially sensitive information. These logs are stored solely on the filesystem in ‘files.log’, with permissions set to 0600, accessible only to the root user.
With the push scheme, it is possible to return HTTP responses indicating the differences to the client that initiated the deployment:
func FilesParser(ApiResponse map[string]interface{}, ClientResponse map[string]interface{}) {
FilesMap, Resp, ActiveParser := ParserGetData(ApiResponse, ClientResponse, "files")
...
for FileName, FileOptions := range FilesMap {
...
GenFile, err := GenTmpFileName(FileName)
if err != nil {
logger.FilesLog.Println("Cannot write temporary file:", GenFile, "with error", err)
Resp[FileName] = map[string]interface{}{
"state": "error",
"error": err.Error(),
}
metrics.FileError.Inc()
continue
}
err = ioutil.WriteFile(GenFile, data, filemode)
if err != nil {
Resp[FileName] = map[string]interface{}{
"state": "error",
"error": err.Error(),
}
logger.FilesLog.Println("Cannot write to file:", FileName, ":", err)
metrics.FileError.Inc()
continue
}
err, result = CompareAndCopyFile(FileName, GenFile, filemode, FileUser, FileGroup) {
if err == nil {
if result {
Resp[FileName] = map[string]interface{}{
"state": "changed",
"diff": CalculatedDiff,
}
metrics.FileDeployed.Inc()
}
} else {
Resp[FileName] = map[string]interface{}{
"state": "error",
"error": err.Error(),
}
metrics.FileError.Inc()
continue
}
}
...This demonstrates a functioning feedback system that provides responses to the push agents. Similar to Ansible or SaltStack, this system enables the ability to observe the results of deployments on hosts and highlight errors. This example also shows how the metrics work. We have a variety of metrics; some function only at the agent level, while others operate on the API/scheduler level.
Regarding the metrics, we measure the number of service restarts and reloads, file changes, attempted package installations, and more. As a result, we can monitor infrastructure-level issues related to package managers and deployment failures. For example, the following graph illustrates problems with package installations within the infrastructure:
Another example measures the last restarts of services over the month caused by our SCM agent:
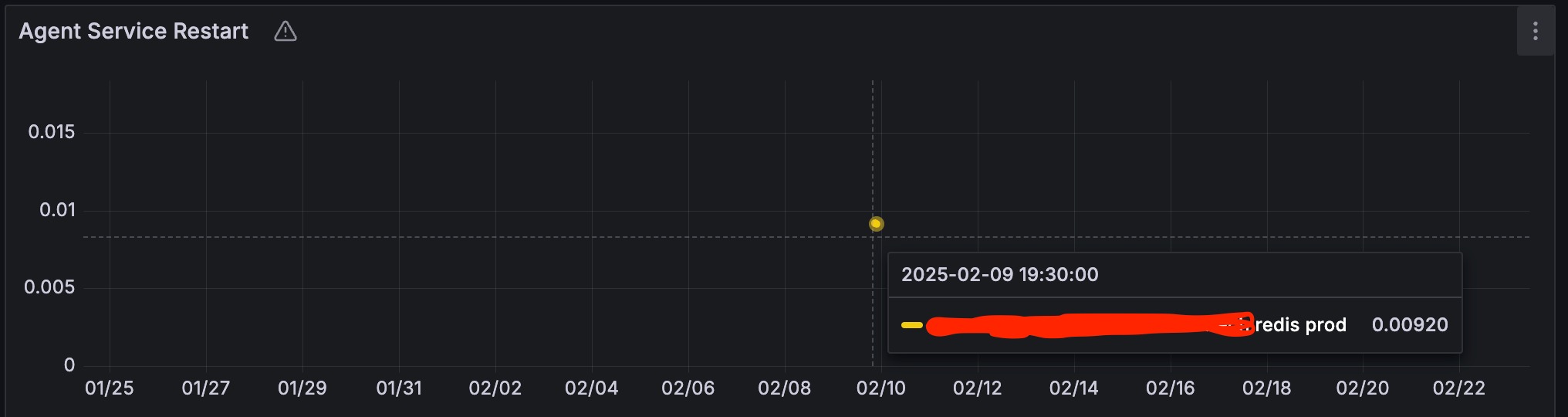
We also have metrics at the API level that measure:
- The delta time between the start of cache generation for all hosts and its completion
- Connection timeouts, refusals, and other issues with data sources
- Cache misses when the agent requests fresh configurations
- Update the rate of the cache
- Newly discovered hosts in the infrastructure
Associated Templates
In our infrastructure, there are not many reasons to use the include instruction in templates or on the software level. For most cases, configurations from templates can be generated automatically, and many of us do not make changes to this. A monofile is a better choice in this situation, as managing one file is simpler than dealing with multiple files in SCM. For example, if you want to carry a file to many servers and then decide to delete it, you would have to create a task to delete that file and subsequently remove its context. In some cases, people may forget to do this and only delete the file from the SCM repository, leaving it unmanaged by the SCM.
With our templating functionality, it is unnecessary to create many file includes, as we are confident that our SCM will generate the configuration for any service regardless. However, there are some approaches where this approach may fail. For example, there are entities with complex configurations that are difficult to template. Some software offers many more options than can be defined by the template, and some of these options may be unstructured. For instance, configuring iptables or nftables can have a complex structure.
Another area of concern is web servers. We have found that both Nginx and Envoy offer a rich set of options, making template creation for these configurations problematic. Additionally, while firewall configurations may not be too large and may not require many files, web servers can describe many projects in a single configuration file. Such configurations can grow to 1 megabyte or even 10MB or more. Manually locating a specific part of the configuration within such a large file is cumbersome, making includes from the templater essential in this case.
As mentioned earlier, using Nginx-level includes is not comfortable for us because it can lead to a loss of control by SCM if a file is deleted. We wanted to create templates at the SCM level and deploy them as a single composed file to the server.
To achieve this, the Go module text/template provides the capability to pass files through a New method with the template name and file contents.
func FileTemplateWithIncludes(ApiResopnse map[string]interface{}, templateFileName string, templatesDirs []string) (string, error) {
templateDirsWithTemplates := make(map[string][]string)
for _, dir := range templatesDirs {
dirPath := conf.LConf.FilesDir + "/data/" + dir
templateDirsWithTemplates[dir] = GetFilesFromDirsBySuffix([]string{dirPath}, conf.LConf.TemplateSuffix)
}
dataMainFile, err := ioutil.ReadFile(templateFileName)
if err != nil {
return string(""), err
}
tmpl, err := template.New(templateFileName).Funcs(sprig.TxtFuncMap()).Parse(string(dataMainFile))
if err != nil {
return string(""), err
}
for relativeTemplateDir, templatesSlice := range templateDirsWithTemplates {
for _, currtentTemplatePath := range templatesSlice {
data, err := ioutil.ReadFile(currtentTemplatePath)
if err != nil {
continue
}
if !strings.HasSuffix(relativeTemplateDir, "https://dzone.com/") {
relativeTemplateDir = relativeTemplateDir + "https://dzone.com/"
}
templateName := relativeTemplateDir + filepath.Base(currtentTemplatePath)
_, err = tmpl.New(templateName).Funcs(sprig.TxtFuncMap()).Parse(string(data))
if err != nil {
continue
}
}
}
templateBuffer := new(bytes.Buffer)
err = tmpl.ExecuteTemplate(templateBuffer, templateFileName, ApiResopnse)
if err != nil {
return string(""), err
}
templateBytes, err := ioutil.ReadAll(templateBuffer)
if err != nil {
return string(""), err
}
file = string(templateBytes)
return file, nil
}However, this changes how we handle template files. Previously, we templated files at the agent level, meaning that the templates were carried to the server as-is, and the file manager would template them at that level. Neither the API nor the scheduler performed templating at their level, which distributed the workload across the infrastructure. This scheme does not work for includes, as it requires all necessary template files to be present on the server where we call the templater. Only the API has access to such files.
We now have an implementation in which the method for templating simple templates or templates with includes is determined by a JSON key.
} else if Fdata.From != "" {
if Fdata.Template == "goInclude" {
GoInclude(DefaultConf, FName)
} else if Fdata.From.(string) != "" {
filesPath := FilesDir + "/data/" + Fdata.From
Fdata.Datadata, err = ioutil.ReadFile(filesPath)
if err != nil {
logger.FilesLog.Println("file read error", FileName, err)
}
}
}Since not many hosts utilize such large configurations, this does not impose a significant load on our SCM’s API. If it does present problems in the future, we could implement transferring a specified directory with templates to the agent and reintroduce configuration templating in a distributed manner.
Example of Creating a New Module
To simplify the process of creating new modules for new team members, we developed a dummy handler that provides a “spherical cow” example of usage applicable in many cases. It looks like this:
var DummyLog *log.Logger
func DummyWaitHealthcheck(Dummy DummyType, ApiResponse map[string]interface{}) bool {
// check for Dummy service is running
return true
}
type DummyType struct {
State string `json:"state"`
PackageName string `json:"package_name"`
ServiceName string `json:"service_name"`
}
func DummyParser(ApiResponse map[string]interface{}, ClientResponse map[string]interface{}) {
dummyData, Resp, ActiveParser := common.ParserGetData(ApiResponse, ClientResponse, "dummy")
if !ActiveParser {
return
}
if DummyLog == nil {
DummyLog = logger.CreateLog("dummy")
}
var dummy DummyType
err := mapstructure.WeakDecode(dummyData, &dummy)
if err != nil {
DummyLog.Println("Err while decode map with mapstructure. Err:", err)
}
DummyFlagName := "dummy.service"
var Hostgroup string
if ApiResponse["Hostgroup"] != nil {
Hostgroup = ApiResponse["Hostgroup"].(string)
}
if common.GetFlag(DummyFlagName) {
LockKey := Hostgroup + "https://dzone.com/" + DummyFlagName
LockRestartKey := "restart-" + DummyFlagName
if common.SharedSelfLock(LockKey, "0", ApiResponse["IP"].(string)) {
DummyLog.Println("common.SharedSelfLock set ok")
if !common.GetFlag(LockRestartKey) {
DummyLog.Println("call RollingRestart")
common.SetFlag(LockRestartKey)
common.DaemonReload()
common.ServiceRestart(DummyFlagName)
}
} else {
DummyLog.Println("No deploy due to find locks in consul:", LockKey)
}
DummyLog.Println("check local flag", LockRestartKey)
if common.GetFlag(LockRestartKey) {
DummyLog.Println("my flag set")
if DummyWaitHealthcheck(dummy, ApiResponse) {
common.SharedUnlock(LockKey)
common.DelFlag(LockRestartKey)
common.DelFlag(DummyFlagName)
}
}
Resp["status"] = "deploying"
} else {
Resp["status"] = "no changes"
}
}
func DummyMerger(ApiResponse map[string]interface{}) {
dummyData, ActiveParser := common.MergerGetData(ApiResponse, "dummy")
if !ActiveParser {
return
}
if DummyLog == nil {
DummyLog = logger.CreateLog("dummy")
}
var dummy DummyType
err := mapstructure.Decode(dummyData, &dummy)
if err != nil {
DummyLog.Println("Err while decode map with mapstructure. Err:", err)
}
DummyService := "dummy.service"
if dummy.ServiceName != "" {
DummyService = dummy.ServiceName
}
if dummy.State != "" {
common.APISvcSetState(ApiResponse, DummyService, dummy.State)
} else {
common.APISvcSetState(ApiResponse, DummyService, "running")
}
DummyPackage := "dummy"
if dummy.PackageName != "" {
DummyPackage = dummy.PackageName
}
common.APIPackagesAdd(ApiResponse, DummyPackage, "", "", []string{}, []string{}, []string{})
Envs := map[string]interface{}{
"DUMMY_SERVICE": "true",
"DUMMY_HOST_ID": "1",
}
common.UsersAdd(ApiResponse, "dummy", Envs, "", "", "", "", 0, []string{}, "", false)
common.DirectoryAdd(ApiResponse, "/var/log/dummy/", "0755", "dummy", "nobody")
common.FileAdd(ApiResponse, false, "/etc/dummy.conf", "dummy/dummy.conf", "go", "present", "root", "root", "", []string{}, []string{}, []string{"dummy.service"}, []string{})
Url := "http://localhost:1112"
AlligatorAddAggregate(ApiResponse, "jmx", Url, []string{})
}By simply copying and pasting, finding and replacing, and making a few edits, they can create their own unique module to configure any other software using the provided code templates. This approach is effective — many people who began developing our SCM started with this experience. However, we still have too little SCM documentation, but we will work on improving it.

{kind=link}